Новости звезд








 привлекают покупателей?")

 Что за прикол про фиаско братан")

Масштабирование информационных систем. Масштабирование нагрузки web-приложений Масштабирование программного обеспечения
С ростом популярности web-приложения его поддержка неизбежно начинает требовать всё больших и больших ресурсов. Первое время с нагрузкой можно (и, несомненно, нужно) бороться путём оптимизации алгоритмов и/или архитектуры самого приложения. Однако, что делать, если всё, что можно было оптимизировать, уже оптимизировано, а приложение всё равно не справляется с нагрузкой?
Оптимизация
Первым делом стоит сесть и подумать, а всё ли вам уже удалось оптимизировать:- оптимальны ли запросы к БД (анализ EXPLAIN, использование индексов)?
- правильно ли хранятся данные (SQL vs NoSQL)?
- используется ли кеширование?
- нет ли излишних запросов к ФС или БД?
- оптимальны ли алгоритмы обработки данных?
- оптимальны ли настройки окружения: Apache/Nginx, MySQL/PostgreSQL, PHP/Python?
Масштабирование
И так, допустим, что оптимизация уже проведена, но приложение всё равно не справляется с нагрузкой. В таком случае решением проблемы, очевидно, может послужить разнесение его по нескольким хостам, с целью увеличения общей производительности приложения за счёт увеличения доступных ресурсов. Такой подход имеет официальное название – «масштабирование» (scale) приложения. Точнее говоря, под «масштабируемостью » (scalability) называется возможность системы увеличивать свою производительность при увеличении количества выделяемых ей ресурсов. Различают два способа масштабирования: вертикальное и горизонтальное. Вертикальное масштабирование подразумевает увеличение производительности приложения при добавлении ресурсов (процессора, памяти, диска) в рамках одного узла (хоста). Горизонтальное масштабирование характерно для распределённых приложений и подразумевает рост производительности приложения при добавлении ещё одного узла (хоста).Понятно, что самым простым способом будет простое обновление железа (процессора, памяти, диска) – то есть вертикальное масштабирование. Кроме того, этот подход не требует никаких доработок приложения. Однако, вертикальное масштабирование очень быстро достигает своего предела, после чего разработчику и администратору ничего не остаётся кроме как перейти к горизонтальному масштабированию приложения.
Архитектура приложения
Большинство web-приложений априори являются распределёнными, так как в их архитектуре можно выделить минимум три слоя: web-сервер, бизнес-логика (приложение), данные (БД, статика).Каждый их этих слоёв может быть масштабирован. Поэтому если в вашей системе приложение и БД живут на одном хосте – первым шагом, несомненно, должно стать разнесение их по разным хостам.
Узкое место
Приступая к масштабированию системы, первым делом стоит определить, какой из слоёв является «узким местом» - то есть работает медленнее остальной системы. Для начала можно воспользоваться банальными утилитами типа top (htop) для оценки потребления процессора/памяти и df, iostat для оценки потребления диска. Однако, желательно выделить отдельный хост, с эмуляцией боевой нагрузки (c помощью или JMeter), на котором можно будет профилировать работу приложения с помощью таких утилит как xdebug , и так далее. Для выявления узких запросов к БД можно воспользоваться утилитами типа pgFouine (понятно, что делать это лучше на основе логов с боевого сервера).Обычно всё зависит от архитектуры приложения, но наиболее вероятными кандидатами на «узкое место» в общем случае являются БД и код. Если ваше приложение работает с большим объёмом пользовательских данных, то «узким местом», соответственно, скорее всего будет хранение статики.
Масштабирование БД
Как уже говорилось выше, зачастую узким местом в современных приложениях является БД. Проблемы с ней делятся, как правило, на два класса: производительность и необходимость хранения большого количества данных.Снизить нагрузку на БД можно разнеся её на несколько хостов. При этом остро встаёт проблема синхронизации между ними, решить которую можно путём реализации схемы master/slave с синхронной или асинхронной репликацией. В случае с PostgreSQL реализовать синхронную репликацию можно с помощью Slony-I , асинхронную – PgPool-II или WAL (9.0). Решить проблему разделения запросов чтения и записи, а так же балансировки нагрузку между имеющимися slave’ами, можно с помощью настройки специального слоя доступа к БД (PgPool-II).
Проблему хранения большого объёма данных в случае использования реляционных СУБД можно решить с помощью механизма партицирования (“partitioning” в PostgreSQL), либо разворачивая БД на распределённых ФС типа Hadoop DFS .
Однако, для хранения больших объёмов данных лучшим решением будет «шардинг » (sharding) данных, который является встроенным преимуществом большинства NoSQL БД (например, MongoDB).
Кроме того, NoSQL БД в общем работают быстрее своих SQL-братьев за счёт отсутствия overhead’а на разбор/оптимизацию запроса, проверки целостности структуры данных и т.д. Тема сравнения реляционных и NoSQL БД так же довольно обширна и заслуживает .
Отдельно стоит отметить опыт Facebook, который используют MySQL без JOIN-выборок. Такая стратегия позволяет им значительно легче масштабировать БД, перенося при этом нагрузку с БД на код, который, как будет описано ниже, масштабируется проще БД.
Масштабирование кода
Сложности с масштабированием кода зависят от того, сколько разделяемых ресурсов необходимо хостам для работы вашего приложения. Будут ли это только сессии, или потребуется общий кеш и файлы? В любом случае первым делом нужно запустить копии приложения на нескольких хостах с одинаковым окружением.Далее необходимо настроить балансировку нагрузки/запросов между этими хостами. Сделать это можно как на уровне TCP (haproxy), так и на HTTP (nginx) или DNS .
Следующим шагом нужно сделать так, что бы файлы статики, cache и сессии web-приложения были доступны на каждом хосте. Для сессий можно использовать сервер, работающий по сети (например, memcached). В качестве сервера кеша вполне разумно использовать тот же memcached, но, естественно, на другом хосте.
Файлы статики можно смонтировать с некого общего файлового хранилища по NFS /CIFS или использовать распределённую ФС (HDFS , GlusterFS , Ceph).
Так же можно хранить файлы в БД (например, Mongo GridFS), решая тем самым проблемы доступности и масштабируемости (с учётом того, что для NoSQL БД проблема масштабируемости решена за счёт шардинга).
Отдельно стоит отметить проблему деплоймента на несколько хостов. Как сделать так, что бы пользователь, нажимая «Обновить», не видел разные версии приложения? Самым простым решением, на мой взгляд, будет исключение из конфига балансировщика нагрузки (web-сервера) не обновлённых хостов, и последовательного их включения по мере обновления. Так же можно привязать пользователей к конкретным хостам по cookie или IP. Если же обновление требует значимых изменений в БД, проще всего, вообще временно закрыть проект.
Масштабирование ФС
При необходимости хранения большого объёма статики можно выделить две проблемы: нехватка места и скорость доступа к данным. Как уже было написано выше, проблему с нехваткой места можно решить как минимум тремя путями: распределённая ФС, хранение данных в БД с поддержкой шардинга и организация шардинга «вручную» на уровне кода.При этом стоит понимать, что раздача статики тоже не самая простая задача, когда речь идёт о высоких нагрузках. Поэтому в вполне резонно иметь множество серверов предназначенных для раздачи статики. При этом, если мы имеем общее хранилище данных (распределённая ФС или БД), при сохранении файла мы можем сохранять его имя без учёта хоста, а имя хоста подставлять случайным образом при формировании страницы (случайным образом балансирую нагрузку между web-серверами, раздающими статику). В случае, когда шардинг реализуется вручную (то есть, за выбор хоста, на который будут залиты данные, отвечает логика в коде), информация о хосте заливки должна либо вычисляться на основе самого файла, либо генерироваться на основании третьих данных (информация о пользователе, количестве места на дисках-хранилищах) и сохраняться вместе с именем файла в БД.
Мониторинг
Понятно, что большая и сложная система требует постоянного мониторинга. Решение, на мой взгляд, тут стандартное – zabbix, который следит за нагрузкой/работой узлов системы и monit для демонов для подстраховки.Заключение
Выше кратко рассмотрено множество вариантов решений проблем масштабирования web-приложения. Каждый из них обладает своими достоинствами и недостатками. Не существует некоторого рецепта, как сделать всё хорошо и сразу – для каждой задачи найдётся множество решений со своими плюсами и минусами. Какой из них выбрать – решать вам.К долгоживущей информационной системе обязательно предъявляется требование масштабируемости (~ изменение размеров), то есть некоторого роста без переписывания всего программного кода и замены всего оборудования.
Система может масштабироваться по трем направлениям: 1) размер (дополнительные пользователи, ресурсы), 2) протяженность в географическом смысле, 3) администрирование (во множестве административно независимых организациях).
Другими словами, масштабируемость включает в себя несколько типов роста: количество пользователей в сети, размер базы данных, сложность транзакций, появление новых приложений.
Количество пользователей в сети. Если оно удвоится, то, скорее всего, удвоится и нагрузка на сеть и базу данных.
Размер базы данных. С увеличением БД до десятков и сотен гигабайт операции резервирования, восстановления и загрузки станут узким местом.
Сложность транзакций. Разработчики приложений делают их все более «умными», облегчая пользователям работу, давая возможность анализировать данные. Но при этом экспоненциально растет число взаимосвязей данных, вследствие чего, во-первых, растет сложность написания, а потому повышается вероятность ошибок. А, во-вторых, при выполнении такой транзакции системе необходимо переработать большое количество данных, что практически может оказаться невозможным для данной мощности процессора, объема оперативной памяти и т.п. Что в свою очередь требует написания каких-то особых алгоритмов выгрузки данных, кэширования и т.п.
Появление новых приложений. Пользователи начинают использовать компьютер в новых областях, что увеличивает нагрузку на существующие сервера. Кроме того, требуется организовывать интеграцию приложений.
Расширяемые системы могут использовать один (или оба!) принципа наращивания мощности вычислительной системы: мультипроцессирование, кластерная технология.
Масштабируемые системы решают проблемы централизации, указанные выше, путем увеличения размеров и мощности сети, серверов, баз данных и приложений простым добавлением аппаратуры. Масштабируемые ИС предоставляют способы роста, благодаря которым увеличение мощности происходит без перепрограммирования приложений или, по крайней мере, без полного перепрограммирования.
На пути масштабируемости стоят
Централизованные службы,
Централизованные данные,
Централизованные алгоритмы.
Централизованная служба предполагает, что некоторая служба (программа) находится только на одном компьютере. В случае если обращения к этой службе от разных клиентов происходят не часто и не одновременно, то это – вполне приемлемое решение. В противном случае такая служба будет узким местом системы. Для того чтобы централизованная служба вызывала меньше проблем, требуется использовать скоростные линии связи, а компьютер, на котором расположена эта служба, должен быть достаточно быстрым, иметь оперативную память и буферы достаточного объема. Несомненное преимущество такой службы состоит в том, что ее легче обновлять. Если служба представляет собой процесс, требующий для своей работы больших вычислительных ресурсов, то может оказаться гораздо выгоднее обеспечить наличие этих ресурсов только на одном компьютере, а не на множестве клиентов. Но, с другой стороны, часто при крахе централизованной службы система в целом теряет работоспособность.
Примером централизованной службы может являться процесс определения прав и полномочий входящих в сеть пользователей. Вы, наверное, замечали, что когда утром одновременно входит в сеть множество пользователей, то ощущается временна я задержка. Если же вы входите в сеть в середине дня, то это происходит быстро. Если же контроллер домена выйдет из строя, то останется только возможность работать с локальным компьютером.
В масштабируемой системе предлагается применять децентрализованные службы. Этого можно достичь двумя путями: либо реплицировав (скопировав) службу на несколько компьютеров, либо (если это возможно) разбив службу на отдельные задачи, разнести соответствующие фрагменты по разным компьютерам. Пример: в достаточно большой локальной сети рекомендуется DHCP сервер (занимающийся выдачей в аренду IP-адресов), хранилище перемещаемых профилей располагать не на контроллере домена, а на отдельном компьютере (конечно же, включенном в нужное время).
Часто централизованная служба связана с централизованными данными. Централизованные данные часто легче защищать (проще устраивать резервное копирование). Но объем таких данных может оказаться настолько большим, что не хватит никаких разумных вычислительных мощностей. В централизованных хранилищах нередко усложняется поиск нужных данных. С одной стороны, время поиска растет при росте хранилища. С другой, в случае централизованного хранилища растет набор признаков – параметров поиска, так как с данными работает большое количество разных задач. Для централизованных данных очень важно делать архивные копии, чтобы снизить возможные потери при поломке централизованного хранилища. Пример централизованных данных – сервер базы данных (MY SQL, MS SQL и т.п.).
Масштабируемая система должна работать с децентрализованными данными. Хороший пример – служба DNS, сопоставляющая символьному имени сетевого ресурса его IP адрес. Архитектура дерева серверов DNS позволяет разделить информацию на фрагменты, каждый из которых поддерживается одним сервером. Между серверами установлена связь и определен протокол их взаимодействия. Обеспечение этой связи – цена применения децентрализованного хранилища. Децентрализованное хранилище обладает некоторым интересным свойством: неодинаковым временем доступа к информации. Для того чтобы сгладить эти различия, то есть с целью ускорения, по крайней мере, повторного доступа к удаленным данным DNS сервера применяют кэширование информации. Но, вы помните, что кэширование приводит к проблеме противоречивости данных. Проблемы, возникающие при децентрализации данных, основная из которых – противоречивость данных на разных компьютерах, рассмотрим чуть позже. Разберем 13 моделей непротиворечивости.
Централизованный алгоритм – тоже плохо для распределенной системы. Алгоритм можно считать централизованным, если для его окончания, то есть для принятия решения, ему требуется полная информация, полученная от непосредственных источников. Вспомним алгоритмы маршрутизации, изученные в курсе «Информационные сети». Рассмотрим в качестве примера централизованного алгоритма «протокол состояния каналов». В этом алгоритме предполагается, что составляющий таблицу маршрутизатор связывается с каждым маршрутизатором. Это приводит к огромному количеству передаваемых служебных пакетов. Этот алгоритм требователен к ресурсам маршрутизатора и к сети, хотя он оказывается слабо чувствителен к исчезновению маршрутизатора. Алгоритм «протокол вектора расстояний» не относится к централизованным алгоритмам, т.к. для принятия решения (построения своей таблицы маршрутизации) маршрутизатору требуется связаться только с соседями. Этот алгоритм гораздо меньше занимает сеть, но может принять неверное решение при исчезновении маршрутизатора (проблема роста расстояния до бесконечности)
Технологии, применяемые при создании масштабируемых систем: скрытие времени ожидания связи, распределение, репликация.
Скрытие времени ожидания часто реализуется за счет асинхронной связи, при которой процесс, запросивший удаленную службу, занимается некоторой работой (не зависимой от ожидаемого ответа) до тех пор, пока не придет ответ. Для того чтобы реализовать это, организуется многопоточное приложение, один из потоков (нитей) которого в случае запроса блокируется и ждет ответа, то есть работает с удаленным сервисом синхронно, а оставшиеся потоки работают асинхронно, то есть продолжают выполнение. Но устроить асинхронное выполнение не всегда возможно, например, при интерактивной работе пользователя с удаленной базой данных. В таком случае рекомендуется устроить, по крайней мере, частичную проверку данных на стороне клиента при помощи скриптов, сократив тем самым количество обращений к удаленной базе данных и, следовательно, уменьшив время ожидания клиента.
Вторая важная технология масштабирования – распределение. Мы уже вспоминали распределенную службу DNS. Важный аспект реализации распределения данных – именование. Проблема состоит в том, что имена должны быть уникальны, то есть требуется тем или иным способом организовать пространства имен. Так же, как и для файлов, у каждого интернет-объекта должно быть уникальное полное имя, включающее имена DNS серверов от объекта до корня DSN.
И, наконец, третья технология – репликация. При репликации все совместно используемые данные или некоторые их части копируются на несколько компьютеров. В результате этого данные можно приблизить к пользователю, уменьшив тем самым время доступа, снизив нагрузку на компьютеры, поддерживающие хранилище. Цена такого решения – необходимость обеспечения непротиворечивости данных. Следует различать репликацию и кэширование. Репликация происходит по инициативе сервера данных (владельца), а кэширование – по инициативе клиента (пользователя).
Если мы имеем дело с кэшированием, то клиент (например, Internet Explorer) должен самостоятельно следить за актуальностью данных. Механизмы, применяемые для этого: а)запросы на обновление данных через определенное время, б) запросы об актуальности (неизменности на сервере). В первом случае может передаваться неизмененное данное, что излишне загружает сеть. А во втором сначала клиент выясняет, изменились ли данные, и только в случае их изменения отправляет запрос на пересылку данных. Очевидно, что если данные изменяются редко, то предпочтительнее использовать второй метод, в противном случае – первый. Теперь – несколько слов о непротиворечивости. В связи с тем, что в распределенной системе могут быть разные клиенты, которым требуется разная степень «свежести» для разных данных, разные данные обладают разным временем обновления и другими характеристиками, а передача данных это – дорогое удовольствие, то в разных случаях потребуются разные методы обеспечения непротиворечивости.
|Постоянно растущее количество посетителей сайта – всегда большое достижение для разработчиков и администраторов. Конечно, за исключением тех ситуаций, когда трафик увеличивается настолько, что выводит из строя веб-сервер или другое ПО. Постоянные перебои работы сайта всегда очень дорого обходятся компании.
Однако это поправимо. И если сейчас вы подумали о масштабировании – вы на правильном пути.
В двух словах, масштабируемость – это способность системы обрабатывать большой объем трафика и приспособляться к его росту, сохраняя при этом необходимый UX. Существует два метода масштабирования:
- Вертикальное (также называется scaling up): увеличение системных ресурсов, например, добавление памяти и вычислительной мощности. Этот метод позволяет быстро устранить проблемы с обработкой трафика, но его ресурсы могут быстро себя исчерпать.
- Горизонтальное (или scaling out): добавление серверов в кластер. Рассмотрим этот метод подробнее.
Что такое горизонтальное масштабирование?
Проще говоря, кластер – это группа серверов. Балансировщик нагрузки – это сервер, распределяющий рабочую нагрузку между серверами в кластере. В любой момент в существующий кластер можно добавить веб-сервер для обработки большего объёма трафика. В этом и есть суть горизонтального масштабирования.
Балансировщик нагрузки отвечает только за то, какой сервер из кластера будет обрабатывать полученный запрос. в основном, он работает как обратный прокси-сервер.
Горизонтальное масштабирование – несомненно, более надёжный метод увеличения производительности приложения, однако оно сложнее в настройке, чем вертикальное масштабирование. Главная и самая сложная задача в этом случае – постоянно поддерживать все ноды приложения обновленными и синхронизированными. Предположим, пользователь А отправляет запрос сайту mydomain.com, после чего балансировщик передаёт запрос на сервер 1. Тогда запрос пользователя Б будет обрабатываться сервером 2.
Что произойдёт, если пользователь А внесёт изменения в приложение (например, выгрузит какой-нибудь файл или обновит содержимое БД)? Как передать это изменение остальным серверам кластера?
Ответ на эти и другие вопросы можно найти в этой статье.
Разделение серверов
Подготовка системы к масштабированию требует разделения серверов; при этом очень важно, чтобы серверы с меньшим объёмом ресурсов имели меньше обязанностей, чем более объёмные серверы. Кроме того, разделение приложения на такие «части» позволит быстро определить его критические элементы.
Предположим, у вас есть PHP-приложение, позволяющее проходить аутентификацию и выкладывать фотографии. Приложение основано на стеке LAMP. Фотографии сохраняются на диске, а ссылки на них – в базе данных. Задача здесь заключается в поддержке синхронизации между несколькими серверами приложений, которые совместно используют эти данные (загруженные файлы и сессии пользователя).
Для масштабирования этого приложения нужно разделить веб-сервер и сервер БД. Таким образом в кластере появятся ноды, которые совместно используют сервер БД. Это увеличит производительность приложения, снизив нагрузку на веб-сервер.
В дальнейшем можно настроить балансировку нагрузки; об этом можно прочесть в руководстве « »
Сессионная согласованность
Разделив веб-сервер и базу данных, нужно сосредоточиться на обработке пользовательских сессий.
Реляционные базы данных и сетевые файловые системы
Данные сессий часто хранят в реляционных базах данных (таких как MySQL), потому что это такие базы легко настроить.
Однако это решение не самое надёжное, потому что в таком случае увеличивается нагрузка. Сервер должен вносить в БД каждую операцию чтения и записи для каждого отдельного запроса, и в случае резкого увеличения трафика база данных, как правило, отказывает раньше других компонентов.
Сетевые файловые системы – ещё один простой способ хранения данных; при этом не требуется вносить изменения в базу исходных текстов, однако сетевые системы очень медленно обрабатывают I/O операции, а это может оказать негативное влияние на производительность приложения.
Липкие сессии
Липкие сессии реализуются на балансировщике нагрузки и не требуют никаких изменений в нодах приложения. Это наиболее удобный метод обработки пользовательских сессий. Балансировщик нагрузки будет постоянно направлять пользователя на один и тот же сервер, что устраняет необходимость распространять данные о сессии между остальными нодами кластера.
Однако это решение тоже имеет один серьёзный недостаток. Теперь балансировщик не только распределяет нагрузку, у него появляется дополнительная задача. Это может повлиять на его производительность и привести к сбою.
Серверы Memcached и Redis
Также можно настроить один или несколько дополнительных серверов для обработки сессий. Это самый надёжный способ решения проблем, связанных с обработкой сессий.
Заключительные действия
Горизонтальное масштабирование приложения сначала кажется очень сложным и запутанным решением, однако оно помогает устранить серьёзные проблемы с трафиком. Главное – научиться работать с балансировщиком нагрузки, чтобы понимать, какие из компонентов требуют дополнительной настройки.
Масштабирование и производительность приложения очень тесно связаны между собой. Конечно, масштабирование нужно далеко не всем приложениям и сайтам. Однако лучше подумать об этом заранее, желательно ещё на стадии разработки приложения.
Tags: ,Означает способность системы, сети или процесса справляться с увеличением рабочей нагрузки (увеличивать свою производительность) при добавлении ресурсов (обычно аппаратных).
Масштабируемость - важный аспект электронных систем, программных комплексов , систем баз данных , маршрутизаторов , сетей и т. п., если для них требуется возможность работать под большой нагрузкой. Система называется масштабируемой , если она способна увеличивать производительность пропорционально дополнительным ресурсам. Масштабируемость можно оценить через отношение прироста производительности системы к приросту используемых ресурсов. Чем ближе это отношение к единице, тем лучше. Также под масштабируемостью понимается возможность наращивания дополнительных ресурсов без структурных изменений центрального узла системы.
В системе с плохой масштабируемостью добавление ресурсов приводит лишь к незначительному повышению производительности, а с некоторого «порогового» момента добавление ресурсов не даёт никакого полезного эффекта.
Вертикальное и
Вертикальное масштабирование
Вертикальное масштабирование - увеличение производительности каждого компонента системы с целью повышения общей производительности. Масштабируемость в этом контексте означает возможность заменять в существующей вычислительной системе компоненты более мощными и быстрыми по мере роста требований и развития технологий. Это самый простой способ масштабирования, так как не требует никаких изменений в прикладных программах, работающих на таких системах.
Горизонтальное масштабирование
Горизонтальное масштабирование - разбиение системы на более мелкие структурные компоненты и разнесение их по отдельным физическим машинам (или их группам), и (или) увеличение количества серверов, параллельно выполняющих одну и ту же функцию. Масштабируемость в этом контексте означает возможность добавлять к системе новые узлы, серверы, процессоры для увеличения общей производительности. Этот способ масштабирования может требовать внесения изменений в программы, чтобы программы могли в полной мере пользоваться возросшим количеством ресурсов.
Показатели
См. также
Примечания
Ссылки
| Это |
Представим, что мы сделали сайт. Процесс был увлекательным и очень приятно наблюдать, как увеличивается число посетителей.
Но в какой-то момент, траффик начинает расти очень медленно, кто-то опубликовал ссылку на ваше приложение в Reddit или Hacker News , что-то случилось с исходниками проекта на GitHub и вообще, все стало как будто против вас.
Ко всему прочему, ваш сервер упал и не выдерживает постоянно растущей нагрузки. Вместо приобретения новых клиентов и/или постоянных посетителей, вы остались у разбитого корыта и, к тому же, с пустой страничкой.
Все ваши усилия по возобновлению работы безрезультатны – даже после перезагрузки, сервер не может справиться с потоком посетителей. Вы теряете трафик!
Никто не может предвидеть проблемы с трафиком. Очень немногие занимаются долгосрочным планированием, когда работают над потенциально высокодоходным проектом, чтобы уложиться в фиксированные сроки.
Как же тогда избежать всех этих проблем? Для этого нужно решить два вопроса: оптимизация и масштабирование .
Оптимизация
Первым делом, стоит провести обновление до последней версии PHP (текущая версия 5.5, использует OpCache ), проиндексировать базу данных и закэшировать статический контент (редко изменяющиеся страницы вроде About , FAQ и так далее).
Оптимизация затрагивает не только кэширование статических ресурсов. Также, есть возможность установить дополнительный не-Apache-сервер (например, Nginx ), специально предназначенный для обработки статического контента.
Идея заключается в следующем: вы помещаете Nginx перед вашим Apache-сервером (Ngiz будет frontend -сервером, а Apache — backend ), и поручаете ему, перехват запросов на статические ресурсы (т.е. *.jpg , *.png , *.mp4 , *.html …) и их обслуживание БЕЗ ОТПРАВЛЕНИЯ запроса на Apache.
Такая схема называется reverse proxy (её часто упоминают вместе с техникой балансировки нагрузки, о которой рассказано ниже).
Масштабирование
Существует два типа масштабирования – горизонтальное и вертикальное .
Мы говорим, что сайт масштабируем, когда он может выдерживать увеличение нагрузки без необходимости внесения изменений в программное обеспечение.
Вертикальное масштабирование
Представьте, что у вас имеется веб-сервер, обслуживающий веб-приложение. Этот сервер имеет следующие характеристики 4GB RAM , i5 CPU и 1TB HDD .
Он хорошо выполняет возложенные на него задачи, но чтобы лучше справляться с нарастающим трафиком, вы решаете заменить 4GB RAM на 16GB, устанавливаете новый i7 CPU и добавляете гибридный носитель PCIe SSD/HDD .
Сервер теперь стал более мощным и может выдерживать увеличенные нагрузки. Именно это и называется вертикальным масштабированием или «масштабированием вглубь » – вы улучшаете характеристики машины, чтобы сделать её более мощной.
Это хорошо проиллюстрировано на изображении ниже:
Горизонтальное масштабирование
С другой стороны, мы имеем возможность произвести горизонтальное масштабирование. В примере, приведенном выше, стоимость обновления железа едва ли будет меньше стоимости первоначальных затрат на приобретение серверного компьютера.
Это очень финансово затратно и часто не дает того эффекта, который мы ожидаем – большинство проблем масштабирования относятся к параллельному выполнению задач.
Если количества ядер процессора недостаточно для выполнения имеющихся потоков, то не имеет значения, насколько мощный установлен CPU – сервер все равно будет работать медленно, и заставит посетителей ждать.
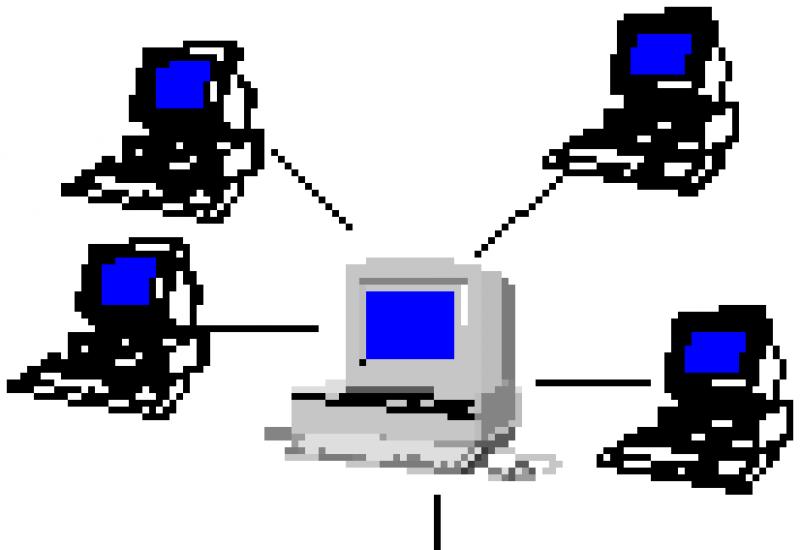
Горизонтальное масштабирование подразумевает построение кластеров из машин (часто достаточно маломощных), связанных вместе для обслуживания веб-сайта.
В данном случае, используется балансировщик нагрузки (load balancer ) – машина или программа, которая занимается тем, что определяет, какому кластеру следует отправить очередной поступивший запрос.
А машины в кластере автоматически разделяют задачу между собой. В этом случае, пропускная способность вашего сайта возрастает на порядок по сравнению с вертикальным масштабированием. Это также известно как «масштабирование вширь ».
Есть два типа балансировщиков нагрузки – аппаратные и программные . Программный балансировщик устанавливается на обычную машину и принимает весь входящий трафик, перенаправляя его в соответствующий обработчик. В качестве программного балансировщика нагрузки, может выступить, например, Nginx .
Он принимает запросы на статические файлы и самостоятельно их обслуживает, не обременяя этим Apache. Другим популярным программным обеспечением для программной балансировки является Squid , который я использую в своей компании. Он предоставляет полный контроль над всеми возможными вопросами посредством очень дружественного интерфейса.
Аппаратные балансировщики представляет собой отдельную специальную машину, которая выполняет исключительно задачу балансировки и на которой, как правило, не установленного другого программного обеспечения. Наиболее популярные модели разработаны для обработки огромного количества трафика.
При горизонтальном масштабировании происходит следующее:
Заметьте, что два описанных способа масштабирования не являются взаимоисключающими – вы можете улучшать аппаратные характеристики машин (также называемых нодами — node ), используемых в масштабированной вширь кластерной системе.
В данной статье мы сфокусируемся на горизонтальном масштабировании, так как в большинстве случаев оно предпочтительнее (дешевле и эффективнее), хотя его и труднее реализовать с технической точки зрения.
Сложности с разделением данных
Имеется несколько скользких моментов, возникающих при масштабировании PHP-приложений. Узким местом здесь является база данных (мы еще поговорим об этом во второй части данного цикла).
Также, проблемы возникают с управлением данными сессий, так как залогинившись на одной машине, вы окажетесь неавторизованным, если балансировщик при следующем вашем запросе перебросит вас на другой компьютер. Есть несколько способов решения данной проблемы – можно передавать локальные данные между машинами, либо использовать постоянный балансировщик нагрузки.
Постоянный балансировщик нагрузки
Постоянный балансировщик нагрузки запоминает, где обрабатывался предыдущий запрос того или иного клиента и, при следующем запросе, отправляет запрос туда же.
Например, если я посещал наш сайт и залогинился там, то балансировщик нагрузки перенаправляет меня, скажем, на Server1 , запоминает меня там, и при следующем клике, я вновь буду перенаправлен на Server1 . Все это происходит для меня совершенно прозрачно.
Но что, если Server1 упал? Естественно, все данные сессии будут утеряны, а мне придется логиниться заново уже на новом сервере. Это очень неприятно для пользователя. Более того, это лишняя нагрузка на балансировщик нагрузки: ему нужно будет не только перенаправить тысячи людей на другие сервера, но и запомнить, куда он их перенаправил.
Это становится еще одним узким местом. А что, если единственный балансировщик нагрузки сам выйдет из строя и вся информации о расположении клиентов на серверах будет утеряна? Кто будет управлять балансировкой? Замысловатая ситуация, не правда ли?
Разделение локальных данных
Разделение данных о сессиях внутри кластера определенно кажется неплохим решением, но требует изменений в архитектуре приложения, хотя это того стоит, потому что узкое место становится широким. Падение одного сервера перестает фатально влиять на всю систему.
Известно, что данные сессии хранятся в суперглобальном PHP-массиве $_SESSION . Также, ни для кого не секрет, что этот массив $_SESSION хранится на жестком диске.
Соответственно, так как диск принадлежит той или иной машине, то другие к нему доступа не имеют. Тогда как же организовать к нему общий доступ для нескольких компьютеров?
Замечу, что обработчики сессий в PHP могут быть переопределены – вы можете определить свой собственный класс/функцию для управления сессиями.
Использование базы данных
Используя собственный обработчик сессий, мы можем быть уверены, что вся информация о сессиях хранится в базе данных. База данных должна находиться на отдельном сервере (или в собственном кластере). В таком случае, равномерно нагруженные сервера, будут заниматься только обработкой бизнес-логики.
Хотя данный подход работает достаточно хорошо, в случае большого трафика, база данных становится не просто уязвимым местом (потеряв её, вы потеряете все), к ней будет много обращений из-за необходимости записывать и считывать данные сессий.
Это становится очередным узким местом в нашей системе. В этом случае, можно применить масштабирование вширь, что проблематично при использовании традиционных баз данных типа MySQL , Postgre и тому подобных (эта проблема будет раскрыта во второй части цикла).
Использование общей файловой системы
Можно настроить сетевую файловую систему, к которой будут обращаться все серверы, и работать с данными сессий. Так делать не стоит. Это совершенно неэффективный подход, при котором велика вероятность потери данных, к тому же, все это работает очень медленно.
Это еще одна потенциальная опасность, даже более опасная, чем в случае с базой данных, описанном выше. Активация общей файловой системы очень проста: смените значение session.save_path в файле php.ini , но категорически рекомендуется использовать другой способ.
Если вы все-таки хотите реализовать вариант с общей файловой системой, то есть гораздо более лучшее решение — GlusterFS .
Memcached
Вы можете использовать memcached для хранения данных сессий в оперативной памяти. Это очень небезопасный способ, так как данные сессий будут перезаписаны, как только закончится свободное дисковое пространство.
Какое-либо постоянство отсутствует – данные о входе будут храниться до тех пор, пока memcached -сервер запущен и имеется свободное пространство для хранения этих данных.
Вы можете быть удивлены – разве оперативная память не отдельна для каждой машины? Как применить данный способ к кластеру? Memcached имеет возможность виртуально объединять всю доступную RAM нескольких машин в единое хранилище:
Чем больше машин у вас в наличии, тем больше будет размер созданного общего хранилища. Вам не нужно вручную распределять память внутри хранилища, однако вы можете управлять этим процессом, указывая, какое количество памяти можно выделить от каждой машины для создания общего пространства.
Таким образом, необходимое количество памяти остается в распоряжении компьютеров для собственных нужд. Остальная же часть используется для хранения данных сессий всего кластера.
В кэш, помимо сессий могут попадать и любые другие данные по вашему желанию, главное чтобы хватило свободного места. Memcached это прекрасное решение, которое получило широкое распространение.
Использовать этот способ в PHP-приложениях очень легко: нужно изменить значение в файле php.ini :
session.save_handler = memcache session.save_path = "tcp://path.to.memcached.server:port"
Redis Cluster
Redis это не SQL хранилище данных, расположенное в оперативной памяти, подобно Memcached , однако оно имеет постоянство и поддерживает более сложные типы данных, чем просто строки PHP-массива в форме пар «key => value ».
Это решение не имеет поддержки кластеров, поэтому реализация его в горизонтальной системе масштабирования не так проста, как может показаться на первый взгляд, но вполне выполняема. На самом деле, альфа-версия кластерной версии уже вышла и можно её использовать.
Если сравнивать Redis с решениями вроде Memcached , то он представляет собой нечто среднее между обычной базой данных и Memcached .
Другие решения:
- ZSCM от Zend – хорошая альтернатива, но требует установки Zend Server на каждый нод в кластере;
- Прочие не SQL хранилища и системы кэширования также вполне работоспособны – ознакомьтесь с Scache , Cassandra или Couchbase , все они работают быстро и надежно.
Заключение
Как вы могли понять из написанного выше, горизонтальное масштабирование PHP-приложений это не пикник на выходных.