Новости звезд
 Что за прикол про фиаско братан")











Соревнования по программированию. Введение в XML-RPC Уклонение xmlrpc php
- Support for creating both xmlrpc clients and servers
- Fully automated or fully manual, fine-grained encoding and decoding from php values to xmlrpc
- Support for UTF8, Latin-1 and ASCII character encodings. With the php mbstring extension enabled, even more character sets are supported.
- Support for http compression of both requests and responses, cookies, proxies, basic auth and https, ntlm auth and keepalives with the php cURL extension
- Optional validation of parameter types of incoming xmlrpc request
- Support for system.listMethods, system.methodHelp, system.multicall and system.getCapabilities methods
- Support for the
and - Possibility to register existing php function or class methods as webservices, extracting value-added information from phpdoc comments
- A web based visual debugger is included with the library
Requirements
- PHP 5.3.0 or later; 5.5 or later recommended
- the php "curl" extension is needed if you wish to use SSL or HTTP 1.1 to communicate with remote servers
- the php "mbstring" extension is needed to allow reception of requests/responses in character sets other than ASCII, Latin-1, UTF-8
- the php "xmlrpc" native extension is not required, but if it is installed, there will be no interference with the operation of this library.
Download
News
- 1st of July, 2017
Released lib versions 4.2.0 and 3.1.0.
The release notes are available on Github - 20th of January, 2016
Released lib version 4.0.0.
This is the first time - ever - that the API sees major changes, doing away with the past and starts a transition to modern-day php.
Namespaces have been introduced, and the default character set in use if UTF-8; support for mbstring has been added, and much more.
For a complete list of changes, head on to on Github - 19th of April, 2015
Released lib version 3.0.1. - 15th of June, 2014
Released lib version 3.0.0. - 15th of December, 2013
The project moved to GitHubOnline xmlrpc debugger
A demo xmlrpc debugger application, built on top of this library, is active at the address http://gggeek.altervista.org/sw/xmlrpc/debugger/ . You can use the debugger to e.g. query the SF demo server, or debug your own personal xmlrpc server, if it is accessible on the net.
Development
Description Status - updated 2009/07/26 Update documentation for all features added since version 2 Slowly progressing... Add the possibility to choose formatting of the xml messages Similar to what the php native xmlrpc extension does Fix warnings emitted when running with PHP 5 in STRICT mode Might have already been done in version 3.0, abandoning php 4 compat... Expand automatic php function to xmlrpc method wrapper to take advantage of exception handling and return xmlrpc error responses Expand automatic stub generator for automatically converting php functions to xmlrpc methods for PHP <= 5.0.2 look at AMFPHP code on how to do it.
Many enhancements in version 2.1
Now that the server can automatically register php functions there is less need for it...Better support for mbstring when it"s enabled Should make e.g. charset encoding guessing faster Improve support for "version 1" cookies Add a possibility to use instead of the native error codes PEAR compatibility: add synonyms for functions existing with different names in the PEAR version of the lib Add support for the xmlrpc extension Add to the debugger the capability to launch a complete set of validator1 tests Examine usability of WSDL for describing exposed services and translation to/from system.methodSignature and system.describeMethods Some problems exist in using an XSD to strictly define xmlrpc. Relax NG is a definitely better alternative, but there is little support in other toolkits for using it in conjunction with a WSDL file... Support http redirects (302) Add to sf.net a small database, so that we can implement a validator page that logs incoming users, such as is present on the xmlrpc.com site Add to benchmark suite the capability to upload results to sf.net Write a php extension that will accelerate the most heavily used functions of the lib See how adodb did it for an example Test speed/memory gains using simplexml and relaxng instead of hand parsing of xml Security
The third security breach: august 2005
This was a further and proactive response to the second security breach below. All use of eval() has been removed since it was still a potential exploit.
When the library was originally written, the versions of php available at the time did not include call_user_func(), et al. So it was written within those constraints to use eval() in two of the functions called by the xml parser. Due to this usage, the server class also used eval() since it had to parse xml using the same functions.
These handler functions, and the array used to maintain the content of the original message, have been rewritten to construct php values instead of building php code for evaluation. This should remove any potential for code execution.
The second security breach: july 2005
The security vulnerability discovered by James Bercegay of GulfTech Security Research on the the 27th of June, 2005, has caused quite a stir. It has made it to the front page of Salshdot, has been mentioned on Netcraft, LWN and many other sites.
Detailed instructions on building exploit code have been released on the internet, and many web hosting administrators are left wondering what is the best defense plan, and what are the real risks. Here are some answers.
Scope of the problem
- the bug affects the two libraries known as PEAR::XMLRPC and PHPXMLRMPC.
It DOES NOT affect the xmlrpc implementation which is built-in in php and enabled at compile time with the "--with-xmlrpc" option (on Unix, on windows generally it is enabled/disabled by changing the appropriate line in php.ini) - the bug (execution of php-code injected by remote hosts) resides exclusively in the file xmlrpc.inc in the phpxmlrpc distribution and RPC.php in the PEAR distribution
- both PEAR::XMLRPC and PHPXMLRMPC have released updated versions of the library that fix the problem
- both libraries have been used in a large number of php applications (see the incomplete list above).
Since the whole lib consists basically of 2 very simple files, everybody tends to patch them according to its own tastes/needs and bundle them when distributing their app.
Most high-profile projects have been extremely quick in releasing new versions of their respective apps, but it will take a much longer time for every single user to update his system.
It has to be said that many applications had been shipping until recently with extremely outdated versions of the phpxmlrpc library included; a first injection bug had been fixed in 2001 without anyone apparently taking notice (...)This makes it unfortunately a lot harder for sysadmins to find an easy cure for the problem: there is a great chance that on public hosting servers the aforementioned files will be found in many different directories and in many different versions.
How the vulnerability is triggered
- to trigger the bug an attacker needs to have some specially crafted xml evaluated in the creation process of an xmlrpcval object. Xmlrpcval objects are created when the server script decodes xmlrpc requests or when some php scripts acts as an xmlrpc client and decodes a response sent by a server.
The server script is application specific, and it is often named server.php (but any project- or user-chosen variant is possible), and it has to include both xmlrpc.inc and xmlrpcs.inc files (for the pear version, server.php is the equivalent of xmlrpcs.inc). - Only including xmlrpc.inc and xmlrpcs.inc in php scripts is (afaik...) completely safe, as well as calling them directly via http requests, since only definition of functions, variables and classes is carried out in those two files, i.e. no immediate code execution.
- The server.php and discuss.php files distributed with full the phpxmlrpc lib actually do implement a live xmlrpc server, so you might consider blocking access to them or even better removing them if you find them deployed on production servers (off the top of my mind I can conjure some kind of attack involving a second php app suffering of a takeover-php-file-inclusion breach to pull them in + exploit the lib known bug)
Means of protection
- Give your web server process as little system privileges as you can. On Unix this generally involves running Apache as user nobody and/or in a jailrooted/chrooted environment. Since the PHP engine runs under the same user as the web server, this is the first line of defense: any php code injected by an attacker will run on the server as a least privileged user, and all damage it could do will be limited to disrupting the php application itself
- Run php in safe mode. If you are a public host and are not doing this, chances are your server has been rooted anyway. This prevents the php scripts from using any function you deem to be unsafe, such as system() or eval()
- The hard block:
find all the existing phpxmlrpc files (xmlrpc.inc and xmlrpcs.inc) and disable them (chmod 0) across the system.
This may of course prevent some user applications from working so you should inform your users at the time you do it. - The soft block:
replace all copies of existing phpxmlrpc files (xmlrpc.inc and xmlrpcs.inc) with the ones coming from version 1.1.1.
This method is unfortunately not 100% guaranteed to keep all apps working. Some internals of the lib objects changed from version 0.9 to 1.0 to 1.1 (e.g. the representation of http headers stored inside an xmlrpcresp object), and if code you have deployed on your servers subclasses them, it might find itself in trouble. The xml sent over-the-wire has changed too with respect to some older versions of the lib (in particular: version 1.0.99.2 wrongly encoded chars outside the ASCII range as html entities, whereas now they are encoded as xml charset entities). A couple of new error response codes have been added, too. Having said that, you should be 95% safe running that script and sit there waiting for users to start yelling something is broken... - the PHP PEAR library is upgradeable with a one-line command, so that"s not really a huge problem:
pear upgrade XML_RPC and to tell whether it"s been upgraded (1.3.1 or later is OK, the latest as of now is 1.3.2):
pear list | grep RPC
Some extra considerations
The file xmlrpcs.inc has been patched too in release 1.1.1 to provide a better user experience. In more detail: sending specially crafted malformed xml to a server would cause the php script to emit a php error instead of returning an appropriate xml response.
According to some, this actually entails a "path disclosure security breach" (i.e. the php error message displayed usually contains sensitive information about filesystem paths), but then any single PHP script suffers of the same security problem if the sysadmin is running production servers with the ini directive display_errors=On.
I also know for a fact that there are many places in xmlrpc.inc where calling a function with an unexpected parameter will generate a php warning or error, and I am not planning to implement strict parameter check for every single function anytime soon - if you aim for that, imho, you might as well code in java in the first place.Is this the end of the world?
I hope not.
The reason is there are tens of PHP applications out there that suffer from code injection exploits. Just take a look at the security track of bulletin boards... and yet a lot of people still think PHP is a good choice for web development.
Remember: security is a process, not a state that can be reached.The first security breach: september 2001
I received this advisory from Dan Libby. With his permission it is reproduced here. Note that this exploit is fixed in revisions 1.01 and greater of XML-RPC for PHP. -- Edd Dumbill Tue Sep 24 2001 =============== PHP Security Hole: potential XML-RPC exploit ============================================ Abstract: Using the latest release of Useful Inc"s php xmlrpc library, version 1.0, it is possible for an attacker to structure the xml in such a way as to trick the xml-rpc library into executing php code on a web server. I was able to execute arbitrary php code, and with php"s safe-mode turned off, system commands. An attacker could easily use this as a gateway for launching viruses. Details: I demonstrated the problem by modifying the server.php example script included with the xmlrpc distribution and then calling it via the client.php script, also part of the distribution. I bypassed the standard server code, and simply echo"d responses back to the client. I was able to get the client to execute arbitrary php code. I then restored the server.php sample to its original state and used telnet to send a modified request. I was also able to make code execute on the server, albeit requiring a slightly different syntax. The attack centers around use of php"s eval() function. Since I knew that the xml-rpc library uses eval to construct its data structures from xml input, it was just a matter of structuring the input xml in such a manner that it: a) is not escaped before being passed to eval b) does not generate a php syntax error Normally, all non numeric data is escaped by the library before being passed to eval. However, it turns out that if you send atag, followed by an unexpected tag, such as , the escaping code will be bypassed and "raw" data will be evaluated instead. Exploiting the client: Here is a typical xml-rpc response: hello world hello world
" on the client side:", "string"); echo " hello world
"; \$waste = array("hello world
"; $waste = array("", "string") It is possible to replace everything between "string"); and \$waste with arbitrary code of just about any length. Finally, here"s one that will print the contents of the current directory:", "string"); echo " "; echo `ls -al`; echo "
"; exit; \$waste = array("system.listMethods ", "string")); echo " if you see a directory listing, I just executed php and system code via xml-rpc.
"; echo "now I will attempt a directory listing using ls -al:\n"; echo `ls -al`; echo " "; echo "I could just have easily invoked rm -rf, or written a program to disk and executed it (eg, a virus) or read some files. Have a nice day.
"; exit; $waste = array(array(" - the bug affects the two libraries known as PEAR::XMLRPC and PHPXMLRMPC.
Использование XML-RPC в PHP для публикации материалов в LiveJournal.com (ЖЖ)
Для начала вам потребуется скачать библиотеку XML-RPC. Наиболее удачной версией мне кажется свободно распространяемая через sourceforge " ": Все примеры ниже будут приведены для этой библиотеки версии 2.2.
Что же такое XML-RPC? RPC расшифровывается как Remote Procedure Call, соответственно на русский это можно перевести как удаленный вызов процедур с помощью XML. Сама методика удаленного вызова процедуры известна давно и используется в таких технологиях, как DCOM, SOAP, CORBA. RPC предназначен для построения распределенных клиент-серверных приложений. Это дает возможность строить приложения, которые работают в гетерогенных сетях, например, на компьютерах различных систем, производить удаленную обработку данных и управление удаленными приложениями. В частности этим протоколом пользуется хорошо известный в России сайт livejournal.com.
Рассмотрим пример, как можно разместить кириллическую запись (а именно с этим часто возникают
проблемы) в ЖЖ. Ниже приведен работающий код с комментариями:
new xmlrpcval($name, "string"), "password" => new xmlrpcval($password, "string"), "event" => new xmlrpcval($text, "string"), "subject" => new xmlrpcval($subj, "string"), "lineendings" => new xmlrpcval("unix", "string"), "year" => new xmlrpcval($year, "int"), "mon" => new xmlrpcval($mon, "int"), "day" => new xmlrpcval($day, "int"), "hour" => new xmlrpcval($hour, "int"), "min" => new xmlrpcval($min, "int"), "ver" => new xmlrpcval(2, "int")); /* на основе массива создаем структуру */ $post2 = array(new xmlrpcval($post, "struct")); /* создаем XML сообщение для сервера */ $f = new xmlrpcmsg("LJ.XMLRPC.postevent", $post2); /* описываем сервер */ $c = new xmlrpc_client("/interface/xmlrpc", "www.livejournal.com", 80); $c->request_charset_encoding = "UTF-8"; /* по желанию смотрим на XML-код того что отправится на сервер */ echo nl2br(htmlentities($f->serialize())); /* отправляем XML сообщение на сервер */ $r = $c->send($f); /* анализируем результат */ if(!$r->faultCode()) { /* сообщение принято успешно и вернулся XML-результат */ $v = php_xmlrpc_decode($r->value()); print_r($v); } else { /* сервер вернул ошибку */ print "An error occurred: "; print "Code: ".htmlspecialchars($r->faultCode()); print "Reason: "".htmlspecialchars($r->faultString()).""\n"; } ?>
В данном примере рассмотрен только один метод LJ.XMLRPC.postevent - полный список возможных команд и их синтаксис (на английском языке) доступен по адресу:
Технология XML-RPC применяется в системе WordPress для разных приятных фишек по типу пингбэков, трекбеков, удаленного управления сайтом без входа в админку и т.п. К сожалению, злоумышленники могут использовать ее для DDoS атаки на сайты. То есть вы создаете красивые интересные WP проекты для себя или на заказ и при этом, ничего не подозревая, можете быть частью ботнета для DDoS`а. Соединяя воедино десятки и сотни тысяч площадок, нехорошие люди создают мощнейшую атаку на свою жертву. Хотя при этом ваш сайт также страдает, т.к. нагрузка идет на хостинг, где он размещен.
Свидетельством такой нехорошей активности могут быть логи сервера (access.log в nginx), содержащие следующие строки:
103.238.80.27 - - «POST /wp-login.php HTTP/1.0» 200 5791 "-" "-"
Но вернемся к уязвимости XML-RPC. Визуально она проявляется в медленном открытии сайтов на вашем сервере или же невозможностью их загрузки вообще (502 ошибка Bad Gateway). В тех.поддержке моего хостера FASTVPS подтвердили догадки и посоветовали:
- Обновить WordPress до последней версии вместе с плагинами. Вообще, если вы следите за , то могли читать о необходимости установки последней 4.2.3. из-за критических замечаний в безопасности (точно также как предыдущих версий). Короче говоря, обновляться полезно.
- Установить плагин Disable XML-RPC Pingback.
Отключение XML-RPC в WordPress
Раньше, как мне кажется, опция включения/отключения XML-RPC была где-то в настройках системы, однако сейчас не могу ее там найти. Поэтому самый простой метод избавиться от нее — использовать соответствующий плагин.

Найти и скачать Disable XML-RPC Pingback либо установив его непосредственно из админки системы. Вам не нужно ничего дополнительно настраивать, модуль сразу же начинает работать. Он удаляет методы pingback.ping и pingback.extensions.getPingbacks из XML-RPC интерфейса. Кроме того, удаляет X-Pingback из HTTP заголовков.
В одном из блогов нашел еще парочку вариантов удаления отключения XML-RPC.
1. Отключение XML-RPC в шаблоне.
Для этого в файл функций темы functions.php добавляется строка:
Последние два метода лично я не использовал, т.к. подключил плагин Disable XML-RPC Pingback — думаю, его будет достаточно. Просто для тех, кто не любит лишние установки, предложил альтернативные варианты.
Несколько дней назад я заметил, что нагрузка моих сайтов на хостинг выросла в разы. Если обычно она составляла в районе 100-120 "попугаев" (CP), то за последние несколько дней она возросла до 400-500 CP. Ничего хорошего в этом нет, ведь хостер может перевести на более дорогой тариф, а то и вовсе прикрыть доступ к сайтам, поэтому я начал разбираться.
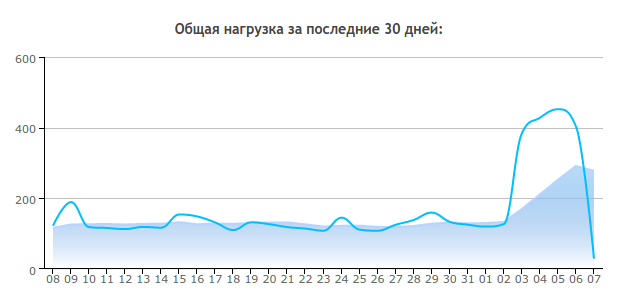
Но я выбрал метод, который позволит сохранить функциональность XML-RPC: установку плагина Disable XML-RPC Pingback . Он удаляет лишь "опасные" методы pingback.ping и pingback.extensions.getPingbacks, оставляя функционал XML-RPC. После установки плагин нужно всего лишь активировать - дальнейшая настройка не требуется.
Попутно я забил все IP атакующих в файл.htaccess своих сайтов, чтобы заблокировать им доступ. Просто дописал в конец файла:
Order Allow,Deny Allow from all Deny from 5.196.5.116 37.59.120.214 92.222.35.159
Вот и все, теперь мы надежно защитили блог от дальнейших атак с использованием xmlrpc.php. Наши сайты перестали грузить хостинг запросами, а также атаковать при помощи DDoS сторонние сайты.
Организация обработки потока с эффективным использованием памяти
Эллиотт Хэролд (Elliot Rusty Harold)
Опубликовано 11.10.2007
PHP 5 представил XMLReader , новый класс для чтения расширяемого языка разметки (XML). В отличие от простого XML или объектной модели документов (DOM) XMLReader работает в потоковом режиме. То есть он считывает документ от начала до конца. Можно начать работать с содержимым документа в его начале, перед тем как вы увидите его окончание. Это делает работу очень быстрой, эффективной и очень экономной с точки зрения затрат памяти. Чем больше размер документов, которые необходимо обрабатывать, тем это важнее.
libxml
Описываемый XMLReader API основывается на libxml-библиотеке Gnome Project для C и C++. На самом деле XMLReader - это всего лишь тонкий PHP-слой на поверхности API libxml XmlTextReader . XmlTextReader также смоделирован на основе (хотя и не имеет общего кода) .NET классов XmlTextReader и XmlReader .
В отличие от простого API для XML (SAX), XMLReader - в большей мере принимающий парсер (pull parser), чем передающий парсер (push parser). Это означает, что программа находится под контролем. Вместо того, чтобы парсер сообщал вам, что он видит, когда он это видит; вы указываете парсеру, когда необходимо переходить к следующему фрагменту документа. Вы запрашиваете контент вместо того, чтобы реагировать на него. Другими словами, это можно представить так XMLReader - это реализация конструктивного шаблона Iterator (итератор), а не конструктивного шаблона Observer (наблюдатель).
Образец задачи
Давайте начнем с простого примера. Представьте, что вы пишете PHP-скрипт, который получает XML-RPC запросы и генерирует ответы. Точнее, представьте, что запросы выглядят, как показано в листинге 1. Корневой элемент документа methodCall , в котором содержатся элементы methodName и params . Название метода - sqrt . Элемент params содержит один элемент param , включающий в себя double - число, квадратный корень которого нужно извлечь. Области имен не используются.
Листинг 1. Запрос XML-RPC
Вот что должен делать PHP-скрипт:
- Проверить название метода и сгенерировать сигнал о сбое (fault response), если это не sqrt (единственный метод, который может быть обработан этим сценарием).
- Найти аргумент и, если он отсутствует или имеет неправильный тип, сгенерировать сигнал о сбое.
- В противном случае вычислить квадратный корень.
- Вернуть результат в форме, показанной в листинге 2.
Листинг 2. Ответ XML-RPC
Давайте рассмотрим это шаг за шагом.
Инициализация парсера и загрузка документа
Первым шагом является создание нового объекта парсера. Сделать это просто:
$reader = new XMLReader();Добавление информации к исходным отправляемым данным
Если вы обнаружите, что $HTTP_RAW_POST_DATA пуст, добавьте следующую строку в файл php.ini:
always_populate_raw_post_data = On
$request = $HTTP_RAW_POST_DATA; $reader->XML($request);Можно проанализировать любую строку, откуда бы вы ее ни взяли. Например, это может быть строковая литеральная константа в программе или содержимое файла. Также можно загрузить данные с внешнего URL при помощи функции open() . К примеру, следующая инструкция готовит один из Atom-каналов для разбора:
$reader->XML("http://www.cafeaulait.org/today.atom");Откуда бы вы ни взяли исходные данные, программа чтения теперь установлена и готова выполнять анализ.
Чтение документа
Функция read() перемещает парсер к следующему маркеру. Самый простой подход заключается в выполнении итераций цикла while по всему документу:
while ($reader->read()) { // обрабатывающий код... }По окончании закройте парсер, чтобы освободить ресурсы, которые он занимает, и перенастройте его для следующего документа:
$reader->close();Внутри цикла парсер помещается в определенном узле: в начале элемента, в конце элемента, в текстовом узле, в комментарии и так далее. Следующие свойства позволяют узнать, что парсер просматривает в данный момент:
- localName - это локальное, предварительно не заданное имя узла.
- name - возможное предварительно заданное имя узла. Для таких узлов, которые не имеют имен, например, комментариев, это #comment , #text , #document , и т. д., как в DOM (объектная модель документов).
- namespaceURI - это унифицированный идентификатор ресурса (URI) для пространства имен узла.
- nodeType - это целое число, представляющее тип узла - к примеру, 2 для узла атрибута и 7 - для оператора обработки.
- prefix - это префикс пространства имен узла.
- value - это текстовое содержание узла.
- hasValue - верно, если узел имеет текстовое значение и неверно в противном случае.
Конечно, не все типы узлов обладают всеми этими свойствами. Например, текстовые узлы, CDATA-разделы, комментарии, операторы обработки, атрибуты, символ пробела, типы документов и описания XML имеют значения. Другие типы узлов (в особенности – элементы и документы) – не имеют. Обычно программа использует свойство nodeType для определения того, что просматривается, и выдачи соответствующего ответа. В листинге 3 показан простой цикл while , который использует эти функции для вывода того, что он просматривает. В листинге 4 показан результат работы этой программы, когда ей на вход подается листинг 1.
Листинг 3. Что видит парсер
while ($reader->read()) { echo $reader->name; if ($reader->hasValue) { echo ": " . $reader->value; } echo "\n"; }Листинг 4. Вывод из листинга 3
methodCall #text: methodName #text: sqrt methodName #text: params #text: param #text: value double #text: 10 double value #text: param #text: params #text: methodCallБольшая часть программ не так универсальна. Они принимают входные данные в особой форме и обрабатывают их определенным образом. В примере XML-RPC нужно считать только один параметр из входных данных: элемент double , который должен быть только один. Чтобы это сделать, найдите начало элемента с именем double:
if ($reader->name == "double" && $reader->nodeelementType == XMLReader::element) { // ... }У этого элемента также есть единственный текстовый дочерний узел, который можно считывать, перемещая парсер к следующему узлу:
if ($reader->name == "double" && $reader->nodeType == XMLReader::ELEMENT) { $reader->read(); respond($reader->value); }Здесь функция respond() создает ответ XML-RPC и отправляет его клиенту. Однако, прежде чем я покажу это, необходимо рассказать еще кое-что. Нет никакой гарантии того, что элемент double в документе запроса содержит только один текстовый узел. Он может содержать несколько узлов, а также комментарии и операторы. Например, это может выглядеть следующим образом:
Вложенные элементы
В данной схеме есть один возможный дефект. Вложенные элементы double , например,
Устойчивое решение проблемы должно обеспечивать получение всех потомков текстового узла double , объединять их в цепочку и только затем конвертировать результат в double . Необходимо избегать любых комментариев или других возможных нетекстовых узлов. Это немного сложнее, но, как показано в листинге 5, не слишком.
Листинг 5. Суммируйте весь текстовый контент элемента
while ($reader->read()) { if ($reader->nodeType == XMLReader::TEXT || $reader->nodeType == XMLReader::CDATA || $reader->nodeType == XMLReader::WHITESPACE || $reader->nodeType == XMLReader::SIGNIFICANT_WHITESPACE) { $input .= $reader->value; } else if ($reader->nodeType == XMLReader::END_ELEMENT && $reader->name == "double") { break; } }Пока весь остальной контент документа можно игнорировать. (Позже я продолжу описание обработки ошибок).
Создание ответа
Как следует из имени, XMLReader предназначен только для чтения. Соответствующий класс XMLWriter сейчас находится в разработке, но еще не готов. К счастью, писать XML гораздо легче, чем его считывать. Во-первых, следует задать тип носителя ответа, используя функцию header() . Для XML-RPC это application/xml . Например:
header("Content-type: application/xml");Листинг 6. Отображение XML
function respond($input) { echo "Можно даже вставить буквенные части ответа прямо в страницу PHP, так же, как это было бы реализовано в HTML. Данная технология показана в листинге 7.
Листинг 7. Буквенный XML
function respond($input) { ?>Обработка ошибок
До настоящего момента подразумевалось, что входной документ оформлен корректно. Однако этого никто не может гарантировать. Как любой парсер XML, XMLReader должен прекратить обработку, как только обнаружит ошибку оформления. Если это происходит, то функция read() возвращает false (ложь).
Теоретически, парсер может обрабатывать данные до первой обнаруженной им ошибки. В моих экспериментах с маленькими документами, однако, он сталкивается с ошибкой почти сразу. Лежащий в основе парсер предварительно анализирует большой участок документа, кэширует его, а затем выдает его по частям. Таким образом, он обычно определяет ошибки на предварительном этапе. В целях безопасности лучше не берите на себя ответственность за то, что сможете выполнить анализ контента до первой ошибки оформления. Более того, не предполагайте, что не увидите никакого контента до ошибки парсера. Если нужно принять только полные, корректно оформленные документы, то убедитесь, что скрипт не делает ничего необратимого до самого конца документа.
Если парсер обнаруживает ошибку в оформлении, то функция read() отображает сообщение об ошибке, аналогичное представленному (если настроен подробный отчет об ошибке, как и должно быть на сервере разработки):
Warning: XMLReader::read() [function.read]: < value>
Вы, возможно, не захотите копировать отчет на страницу HTML, представляемую пользователю. Лучше фиксировать сообщение об ошибке в переменной среды $php_errormsg . Для этого нужно включить опцию конфигурации track_errors в файле php.ini:
track_errors = OnПо умолчанию опция track_errors отключена, что явно указано в php.ini, поэтому не забудьте изменить эту строку. Если вы добавите строку, показанную выше, в начало php.ini, то строка track_errors = Off , которая написана ниже, заменит ее.
Эта программа должна посылать ответы только на полные, правильно оформленные входные данные. (Также достоверные, но об этом позже.) Таким образом, нужно подождать завершения анализа документа (выход из цикла while). Теперь проверьте, изменилось ли значение $php_errormsg . Если нет, то документ оформлен корректно, и будет отправлено ответное сообщение XML-RPC. Если переменная задана, то это означает, что документ оформлен некорректно, и будет отправлен сигнал о сбое XML-RPC. Также сигнал о сбое отправляется, если запрашивается квадратный корень отрицательного числа. Смотрите листинг 8.
Листинг 8. Проверка корректного оформления
// отправка запроса (request) $request = $HTTP_RAW_POST_DATA; error_reporting(E_ERROR | E_WARNING | E_PARSE); if (isset($php_errormsg)) unset(($php_errormsg); // создание программы считывания (reader) $reader = new XMLReader(); // $reader->setRelaxNGсхемой("request.rng"); $reader->XML($request); $input = ""; while ($reader->read()) { if ($reader->name == "double" && $reader->nodeType == XMLReader::ELEMENT) { while ($reader->read()) { if ($reader->nodeType == XMLReader::TEXT || $reader->nodeType == XMLReader::CDATA || $reader->nodeType == XMLReader::WHITESPACE || $reader->nodeType == XMLReader::SIGNIFICANT_WHITESPACE) { $input .= $reader->value; } else if ($reader->nodeType == XMLReader::END_ELEMENT && $reader->name == "double") { break; } } break; } } // проверка корректного оформления входной информации if (isset($php_errormsg)) fault(21, $php_errormsg); else if ($input < 0) fault(20, "Cannot take square root of negative number"); else respond($input);Здесь приведена упрощенная версия общего шаблона обработки потоков XML. Парсер заполняет структуру данных, в соответствии с которой выполняются действия, когда документ заканчивается. Обычно структура данных проще, чем сам документ. Здесь структура данных особенно простая: единственная строка.
Валидация
Версия libxml
В ранних версиях libxml , библиотеки, от которой зависит XMLReader , присутствовали серьезные недочеты RELAX NG. Убедитесь, что вы используете хотя бы версию 2.06.26. Многие системы, в том числе Mac OS X Tiger, содержат более ранний выпуск с недочетами.
До сих пор я не придавал большого значения проверке того, действительно ли данные находятся там, где я думаю. Самый простой способ осуществить эту проверку – сравнить документ со схемой. XMLReader поддерживает язык описания схемы RELAX NG; в листинге 9 показана простая схема RELAX NG для данной конкретной формы запроса XML-RPC.
Листинг 9. Запрос XML-RPC
Схему можно добавить непосредственно в PHP-скрипт в виде строкового литерала при помощи setRelaxNGSchemaSource() или считать ее из внешнего файла или URL с помощью setRelaxNGSchema() . Например, при условии, что содержимое листинга 9 записано в файле sqrt.rng, схема будет загружаться следующим образом:
reader->setRelaxNGSchema("sqrt.rng")Выполните это прежде , чем начнете анализировать документ. Парсер сравнивает документ со схемой во время чтения. Чтобы проверить, является ли документ достоверным, вызовите функцию isValid() , которая возвращает значение true, если документ валиден (на данном этапе) и false в противном случае. В листинге 10 показана полная логически завершенная программа, содержащая обработку всех ошибок. Программа должна принимать любые достоверные входные данные и возвращать правильные значения и отклонять все неправильные запросы. Я также добавил метод fault() , который отправляет сигнал о сбое XML-RPC, если что-то идет не так.
Листинг 10. Полная серверная часть извлечения квадратного корня XML-RPC
Атрибуты
Атрибуты не видны при нормальном выполнении анализа. Чтобы считать атрибуты, необходимо остановиться в начале элемента и запросить конкретный атрибут либо по имени, либо по номеру.
Передайте имя атрибута, значение которого необходимо найти в текущем элементе, функции getAttribute() . К примеру, следующая конструкция запрашивает атрибут id текущего элемента:
$id = $reader->getAttribute("id");Если атрибут - в пространстве имен, например, xlink:href , то вызовите getAttributeNS () и передайте локальное имя и URI пространства имен в качестве первого и второго аргументов соответственно (префикс не имеет значения). Например, данная инструкция запрашивает значение атрибута xlink:href в пространстве имен http://www.w3.org/1999/xlink/:
$href = $reader->getAttributeNS ("href", "http://www.w3.org/1999/xlink/");Если атрибут не существует, то оба метода возвратят пустую строку. (Это неправильно, так как они должны вернуть null. Данная реализация усложняет возможность различать атрибуты, значение которых - пустая строка, и те, которые вообще отсутствуют.)
Порядок атрибутов
В XML-документах порядок атрибутов не имеет значения и не сохраняется парсером. Он использует номера для индексирования атрибутов просто ради удобства. Нет гарантии, что первый атрибут в открывающем теге будет атрибутом 1, второй будет атрибутом 2 и т.д. Не создавайте код, зависящий от порядка атрибутов.
Если нужно знать все атрибуты элемента, а их имена заранее неизвестны, то вызовите moveToNextAttribute() , когда считывающая часть установлена на элементе. Если парсер находится на узле атрибута, то можно считать его имя, пространство имен и значение при помощи тех же свойств, которые использовались для элементов. Например, следующий фрагмент кода распечатывает все атрибуты текущего элемента:
if ($reader->hasAttributes and $reader->nodeType == XMLReader::ELEMENT) { while ($reader->moveToNextAttribute()) { echo $reader->name . "="" . $reader->value . ""\n"; } echo "\n"; }Очень необычно для XML API то, что XMLReader позволяет считывать атрибуты либо с начала, либо с конца элемента. Чтобы избежать двойного отсчета, важно убедиться, что типом узла является XMLReader::ELEMENT , а не XMLReader::END_ELEMENT , у которого тоже могут быть атрибуты.
Заключение
XMLReader - полезное дополнение к инструментарию программиста PHP. В отличие от SimpleXML это полный парсер XML, который обрабатывает все документы, а не только некоторые из них. В отличие от DOM он может обрабатывать документы большие, чем доступная память. В отличие от SAX он устанавливает контроль над программой. Если PHP-программам нужно принимать входные данные XML, то стоит всерьез задуматься об использовании XMLReader .